QA With RAG#
官方文档:https://python.langchain.com/v0.2/docs/how_to/#qa-with-rag
from langchain_openai import ChatOpenAI
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
import langchain
langchain.debug = True # 开启debug
# 加载数据从webBase,这里也可以是使
loader = WebBaseLoader(
web_paths=("https://guangzhengli.com/blog/zh/vector-database/",),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
## 上面已经构建好了向量数据库,创建好了retriever
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
contextualize_q_system_prompt = (
"""
给你一个聊天历史和最新的用户问题,这个问题可能会引用聊天历史中的内容,如果聊天历史中有相关的内容,
需要结合聊天内容,形成一个独立的问题,如果没有,原样复述。不要解释输出的内容,
也不要尝试回答问题,否则你会受到惩罚。
"""
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
print(contextualize_q_prompt.pretty_repr())
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
create_history_aware_retriever创建的这个chan可以从retrieve中检索document。
如果没有chat_history,会直接将输入传给retriever,如果有chat_history,会使用promot和llm生成一个search的query,然后再将query待入到retriever中去
system_prompt = """
你是一个问题回答任务的助理。
使用以下检索到的上下文片段来回答问题。
如果你不知道答案,说出你不知道。
最多使用三个句子,并保持回答简洁。
{context}
"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
print(qa_prompt.pretty_repr())
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
create_stuff_documents_chain是将传入chain的文档格式化全部塞给模型。
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
create_retrieval_chain会创建一个检索的chain,他可以检索documents 并且传递给后面的chain
# ChatMessageHistory 是将数据保存在内存中的,这里为了方便,需要一个map缓存一下
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 最终创建一个带有History的chain
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
res = conversational_rag_chain.invoke(
{"input": "向量数据库是什么"},
config={
"configurable": {"session_id": "abc123"}
}, # constructs a key "abc123" in `store`.
)
print(res)
## 再次对话,会结合对话历史,答案形成一个新的问题,然后在用retrieve检索。
res = conversational_rag_chain.invoke(
{"input": "他的特点是什么?"},
config={
"configurable": {"session_id": "abc123"}
}, # constructs a key "abc123" in `store`.
)
可以从上面的执行过程中可以看到。从LangSmith中可以看到
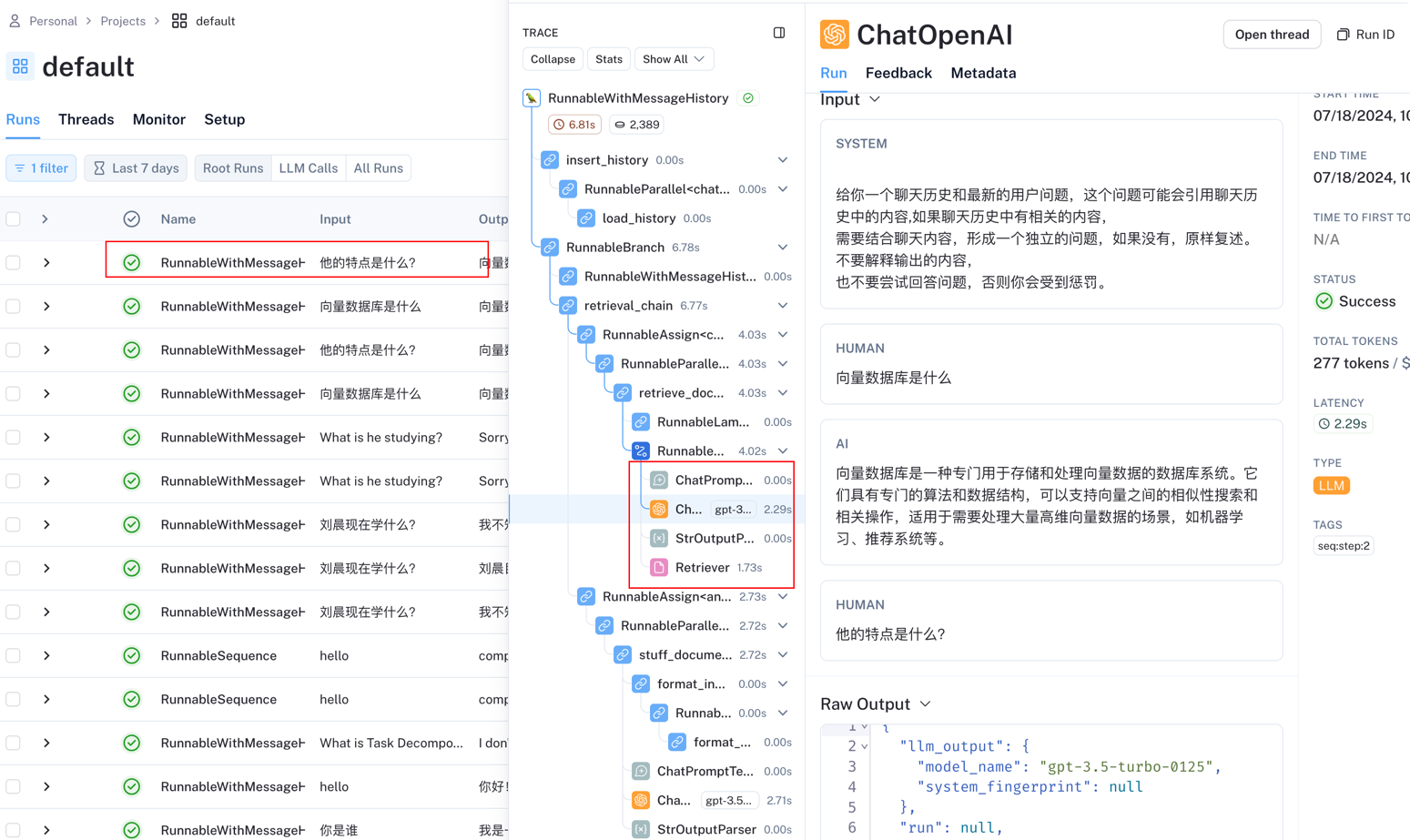
上面的例子中,结合了检索,History,我们在来顺一下上面的流程
首先创建了
create_history_aware_retriever,他本质上是一个retriever,他的作用是增强检索。也就是说,如果有对话历史,会将对话历史和输入的问题塞给llm,让llm结合对话历史提出一个新的问题,比如第一次问向量数据库是什么?,第二次问他有什么特点?,如果单独把最后一个问题代入到Retrieve中去,就会找到一些无效的答案。把这些对话历史给llm,llm就会知道这里的他指的是向量数据库。所以,新的问题是向量数据库的特点?,这样检索出来的内容就很丰富,很符合。创建了
create_stuff_documents_chain,他本质上是一个chain,它的作用是将传入的Document对象格式化,然后将他传入到后面的流程中去,并且传入的key为context, 所以,这就要求调用invoke的时候传入的dict中有key为context元素,并且value是Document的数组。它就是传入的文档(LangChain对外部数据做了封装,统称为Document)创建了
create_retrieval_chain,将前面create_history_aware_retriever,create_stuff_documents_chain包装在里面。他的作用是,将retrieve和chain结合在一起。并且在最终的返回值中,并且在最终的返回中有两个keycontext和answer,一个是retrieve的值,一个是chain的最终的结果.
create_retrieval_chain的源码不太好理解,下面会有demo解释,先在这里做一个说明retrieval_chain = ( RunnablePassthrough.assign( context=retrieval_docs.with_config(run_name="retrieve_documents"), ).assign(answer=combine_docs_chain) ).with_config(run_name="retrieval_chain")这里是用
RunnablePassthrough嵌套执行的方法,意思是:调用retrieval_chain的时候会先将所有的input代入到retrieval_docs执行,拿到结果,将所有的结果代入到combine_docs_chain中执行,最终输出的dict中会有context和answer
到这里,整体的chain已经结束了,使用
RunnableWithMessageHistory来创建一个带有History的chain。
感触:
LangChain很强大,但是也很严格,比如参数的类型,比如说,Retrieve中的context比如和stuff chain中的context 这个key必须得一样,必须得有一个context的key,否则在stuff chain中就找不到了。
还有类似的,chat_history的key,如果没有这个key,在retrieve的时候就不会去使用llm来做问题的增强了。因为在create_history_aware_retriever中key已经固定了。
整体的流程是:当用户输入问题
先保存对话历史(用户输入的问题,通过session id)
做retrieve。
如果有对话历史就使用llm来增强,增强问题,再次查找
如果没有,就直接查找
retrieve会返回Document,将这些document和chat_history会全部导入到prompt中和LLM交互
保存对话历史(AI返回值)
输出。
解释RunnableParallel和RunnablePassthrough#
解释他的目的是为了更好的理解LangChain的LCEL,上面demo中源码里面有它。
RunnableParallel#
它是一个Runnable,我们一开始说了,Runnable就是一个LCEL的顶级接口。所以,它的使用方式和chain是一样的,按照这个思路理解是ok的。
它的作用是,并行运行他里面每一个Runnable。
from langchain_core.runnables import RunnableLambda
def add_one(x: int) -> int:
return x + 1
def mul_two(x: int) -> int:
return x * 2
def mul_three(x: int) -> int:
return x * 3
# RunnableLambda 转化python代码(callable)为一个Runnable
runnable_1 = RunnableLambda(add_one)
runnable_2 = RunnableLambda(mul_two)
runnable_3 = RunnableLambda(mul_three)
sequence = runnable_1 | { # this dict is coerced to a RunnableParallel
"mul_two": runnable_2,
"mul_three": runnable_3,
}
sequence.invoke(1)
这里面的代码就是首先将1传入到add_one返回2,之后将2各自输入到mul_two和mul_three,得到最终的代码,从上面的debug流程中也可以看到,上面的代码其实等于
from langchain_core.runnables import RunnableParallel
# LangChain自动对dict做了包装
chain = runnable_1 | RunnableParallel(
mul_two=runnable_2,
mul_three=runnable_3,
)
chain.invoke(1)
实际的使用是,可以并行的调用两个chain,如下 这里的demo会让LangChain将对一个主题,做两个事情。
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI()
joke_chain = (
ChatPromptTemplate.from_template("tell me a joke about {topic}")
| model
| StrOutputParser()
)
poem_chain = (
ChatPromptTemplate.from_template("write a 2-line poem about {topic}")
| model
| StrOutputParser()
)
parallel_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)
res = parallel_chain.invoke({"topic": "太阳"})
print(res)
RunnableSequence#
和上面相对应的是RunnableSequence,一个一个执行,前面的执行完了,前面的值作为后面的输入。
RunnableSequence支持配置first,middle,last。按照执行顺序来
from langchain_core.runnables import RunnableLambda, RunnableSequence
def add_one(x: int) -> int:
return x + 1
def add_two(x: int) -> int:
return x + 2
def mul_two(x: int) -> int:
return x * 2
runnable_1 = RunnableLambda(add_one)
runnable_2 = RunnableLambda(add_two)
runnable_3 = RunnableLambda(mul_two)
sequence = RunnableSequence(first=runnable_1, middle=[runnable_2], last=runnable_3)
# Or equivalently:
# sequence = runnable_1 | runnable_2
sequence.invoke(1)
实际使用场景
还记得 prompt | model | SimpleJsonOutputParser()不?,他本质上就是构建了一个RunnableSequence。
RunnablePassthrough#
他可以传递或者改变或者增加一个额外的key给后续的流程,都是要配合RunnableSequence或者RunnableParallel来使用的。否则没有意义。并且他也实现了Runnable
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
runnable = RunnableParallel(
origin=RunnablePassthrough(),
modified=lambda x: x + 1
)
runnable.invoke(1) # {'origin': 1, 'modified': 2}
在某些情况下,需要将输入透传给后面,并且在添加一些额外的key,这个情况下可以使用assign方法
RunnablePassthrough.assign()意思就是,将原来的输入的input,传递给assign里面,在这里可以对输入值做二次加工。
from langchain_core.runnables import RunnablePassthrough
def fake_llm(prompt: str) -> str: # Fake LLM for the example
return "completion"
runnable = {
'llm1': fake_llm,
'llm2': fake_llm,
} | RunnablePassthrough.assign(
total_chars=lambda inputs: len(inputs['llm1'] + inputs['llm2'])
)
runnable.invoke('hello')
看一下assign方法的实现
@classmethod
def assign(
cls,
**kwargs: Union[
Runnable[Dict[str, Any], Any],
Callable[[Dict[str, Any]], Any],
Mapping[
str,
Union[Runnable[Dict[str, Any], Any], Callable[[Dict[str, Any]], Any]],
],
],
) -> "RunnableAssign":
### 滴滴滴,看这里,它是将传递进来的参数包装成了一个 RunnableParallel
return RunnableAssign(RunnableParallel(kwargs))
所以,他的assign方法就是手动构建了一个RunnableParallel,并且将inut传入到了里面。他传入的input就是当前他所在的RunnableParallel或者RunnableSequence的input。
key看下面的例子,text_input 的输入就是 上一个阶段的输入。
runnable = {
'llm1': fake_llm,
'llm2': fake_llm,
} | RunnablePassthrough.assign(
total_chars=lambda inputs: len(inputs['llm1'] + inputs['llm2']),
text_input=RunnablePassthrough()
)
runnable.invoke(1)
那按照这个逻辑来说,就有下面的代码。
runnable = ({
'llm1': fake_llm,
'llm2': fake_llm,
} # 1
| RunnablePassthrough.assign(
total_chars=lambda inputs: len(inputs['llm1'] + inputs['llm2']),
) # 2
.assign( # 3
test=RunnablePassthrough()
))
runnable.invoke(1)
解释:
在#1,创建的是RunnableParallel,有两个阶段llm1,llm2并行执行,拿到结果,将值传递给#2,#2拿到input之后,做了操作,增加了total_chars后,传递给了#3,#3,#3创建了一个key叫做test,test里面存放的是之前所有的输入。所以他的结果是
{'llm1': 'completion',
'llm2': 'completion',
'total_chars': 20,
'test': {'llm1': 'completion', 'llm2': 'completion', 'total_chars': 20}}
end