结构化结果和工具调用#
结构化结果#
LLM返回结构化数据这一功能极具实用价值,例如从数据中提取接口参数,亦或是将数据存储于数据库。 接下来介绍几种相关方法
with_structured_output方法#
这是模型所提供的原生 API 用于输出结构化数据,此方式是最为简单且可靠的。不管是工具调用、函数调用还是 json 模型,其底层实现均采用这种模式。 有一部分模型并不支持这一方法,而支持的 LLM 如下所示: https://python.langchain.com/v0.2/docs/integrations/chat/
from langchain_openai import ChatOpenAI
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import Optional
# 开启debug
from langchain.globals import set_debug
set_debug(True)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
class Joke(BaseModel):
"""Joke to tell user."""
setup: str = Field(description="The setup of the joke")
punchline: str = Field(description="The punchline to the joke")
rating: Optional[int] = Field(description="How funny the joke is, from 1 to 10")
structured_llm = llm.with_structured_output(Joke)
structured_llm.invoke("Tell me a joke about cats")
可以看到上面在模型的返回中text是没有值的,在kwargs.additional_kwargs.tool_calls中返回了json,按照既定格式要求返回了数据。LangSmith如下:
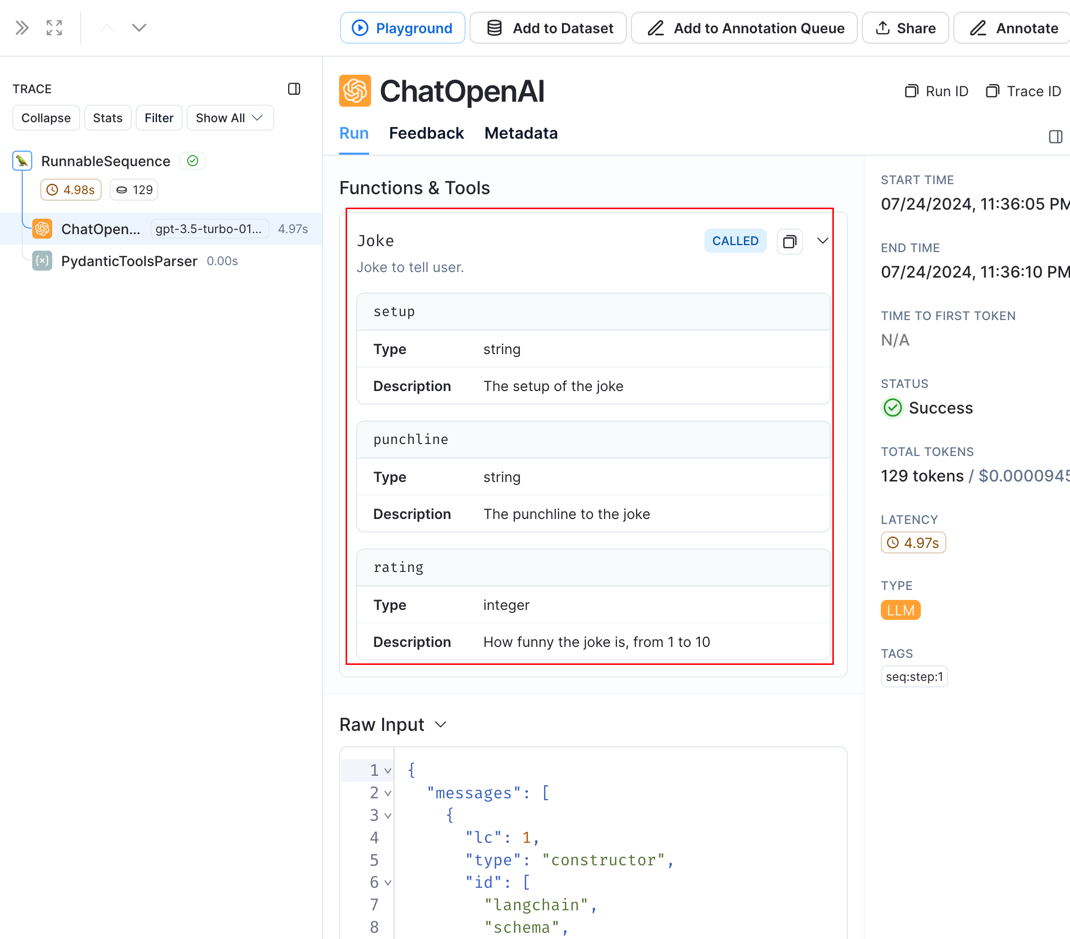 可以看到,这里将模型转为了
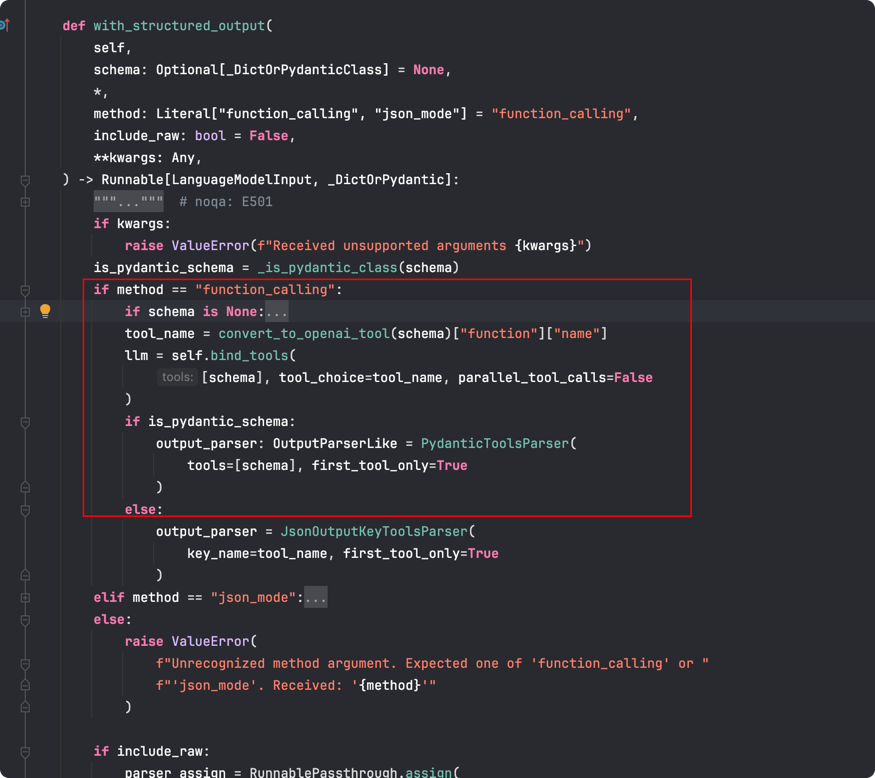
可以看到,这里将模型转为了函数调用,所以,这里的实现还是 function tools,查看with_structured_output源码可以证明
也可以将schema的定义通过json的形式传递来,这样返回值是dict
json_schema = {
"title": "joke",
"description": "Joke to tell user.",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "The setup of the joke",
},
"punchline": {
"type": "string",
"description": "The punchline to the joke",
},
"rating": {
"type": "integer",
"description": "How funny the joke is, from 1 to 10",
},
},
"required": ["setup", "punchline"],
}
structured_llm = llm.with_structured_output(json_schema)
structured_llm.invoke("Tell me a joke about cats")
在多个返回值类型中选择#
可以规定多个类型,让模型在里面做选择,如下所示
from typing import Union
class ConversationalResponse(BaseModel):
"""Respond in a conversational manner. Be kind and helpful."""
response: str = Field(description="A conversational response to the user's query")
class Response(BaseModel):
output: Union[Joke, ConversationalResponse]
structured_llm = llm.with_structured_output(Response)
structured_llm.invoke("Tell me a joke about cats")
# 选择了 Joke
# 选择了ConversationalResponse
structured_llm.invoke("How are you today?")
Streaming#
也支持流式输出
structured_llm = llm.with_structured_output(Response)
set_debug(False)
for chunk in structured_llm.stream("Tell me a joke about cats"):
print(chunk,type(chunk))
Few-shot prompting#
对于更复杂的模式,向提示添加少量示例非常有用。这可以通过几种方式来实现。 最简单的方式是将Example直接添加到system中
from langchain_core.prompts import ChatPromptTemplate
set_debug(True)
system = """You are a hilarious comedian. Your specialty is knock-knock jokes. \
Return a joke which has the setup (the response to "Who's there?") and the final punchline (the response to "<setup> who?").
Here are some examples of jokes:
example_user: Tell me a joke about planes
example_assistant: {{"setup": "Why don't planes ever get tired?", "punchline": "Because they have rest wings!", "rating": 2}}
example_user: Tell me another joke about planes
example_assistant: {{"setup": "Cargo", "punchline": "Cargo 'vroom vroom', but planes go 'zoom zoom'!", "rating": 10}}
example_user: Now about caterpillars
example_assistant: {{"setup": "Caterpillar", "punchline": "Caterpillar really slow, but watch me turn into a butterfly and steal the show!", "rating": 5}}"""
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{input}")])
few_shot_structured_llm = prompt | structured_llm
few_shot_structured_llm.invoke("what's something funny about woodpeckers")
(Advanced) Specifying the method for structuring outputs#
是用json_mode的形式,需要在promot中指定JSON返回值,并且schema的key。
with_structured_output支持两种模型,一种是function_calling 如上所述,一种是json_mode, 在json_mode下,不会将schema包装为function tools给llm,而是一个promot,所以需要在promot中规定返回的json格式。源码和LangSmith如下
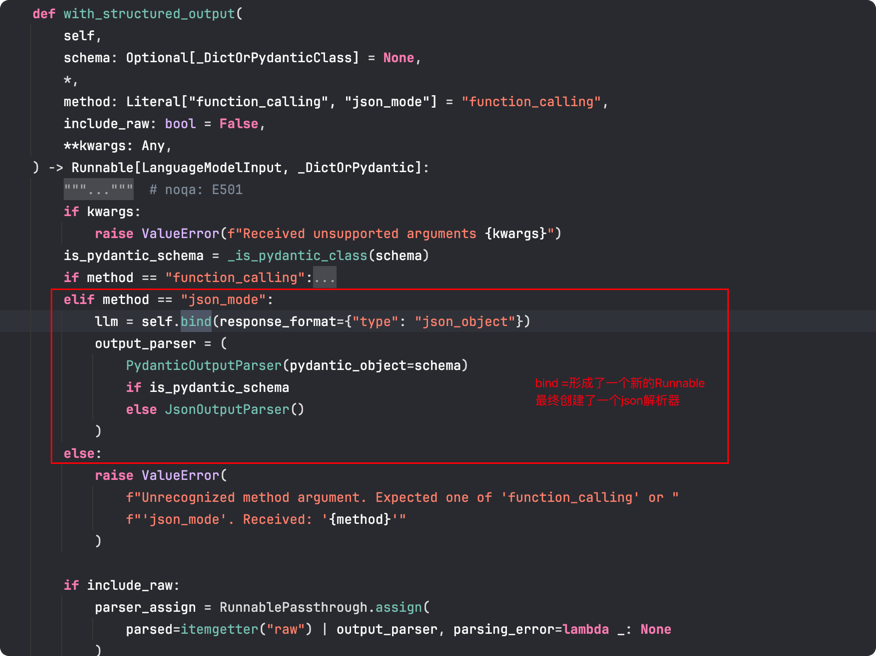
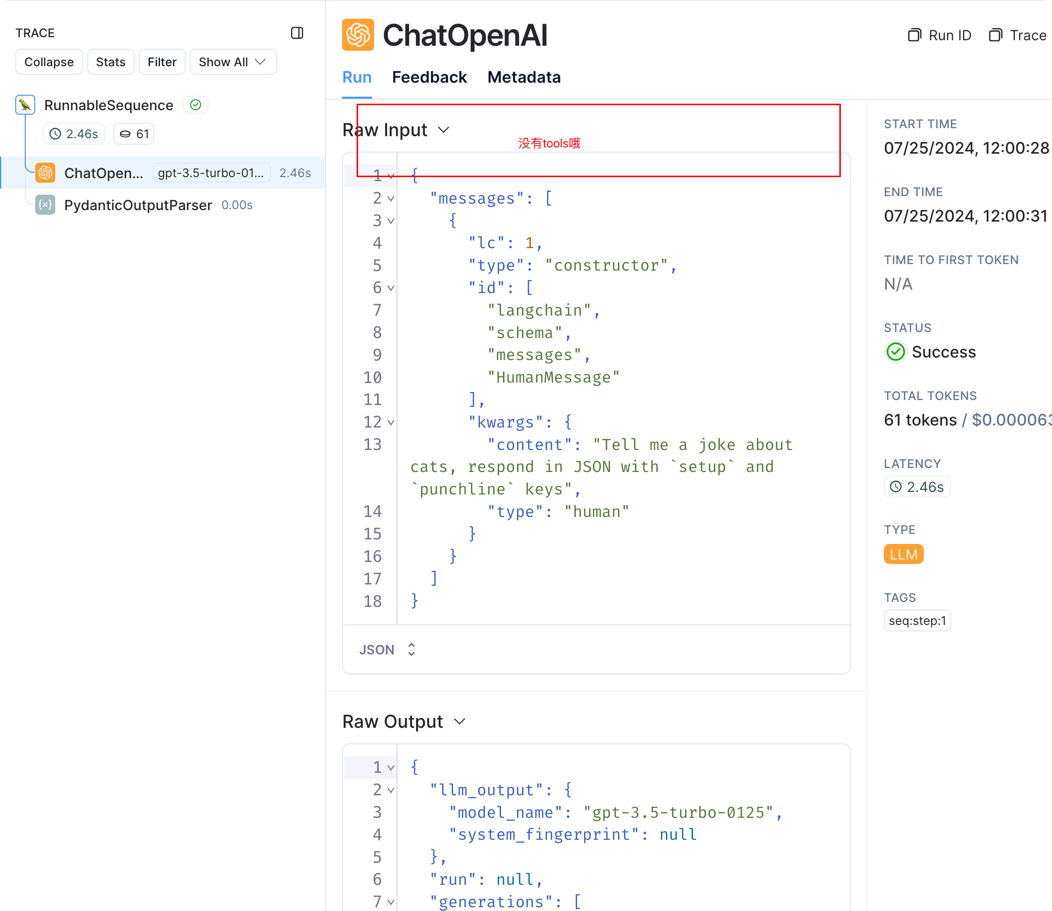
structured_llm = llm.with_structured_output(Joke, method="json_mode")
structured_llm.invoke(
"Tell me a joke about cats, respond in JSON with `setup` and `punchline` keys"
)
(Advanced) Raw outputs#
LLMs 在生成结构化输出时并非尽善尽美,尤其是当模式趋于复杂的时候。您可以通过传递 include_raw=True 这一参数,以避免引发异常,并自行去处理原始输出。这样做将会改变输出的格式,其中会包含原始消息输出(raw)、解析后的值(若成功解析)(parsed)以及任何产生的错误(parsing_error)。
structured_llm = llm.with_structured_output(Joke, include_raw=True)
res = structured_llm.invoke(
"Tell me a joke about cats, respond in JSON with `setup` and `punchline` keys"
)
print(res)
res.keys()
res["parsed"]
自己写promot,自己解析输出值#
并非所有模型都支持 .with_structured_output() 这一功能,原因在于并非所有模型都支持工具调用或 JSON 模式。对于这类模型,你的直接提示模型采用特定的格式,同时使用输出解析器从原始的模型输出里提取结构化的响应。
PydanticOutputParser#
from typing import List
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
name: str = Field(..., description="The name of the person")
height_in_meters: float = Field(
..., description="The height of the person expressed in meters."
)
class People(BaseModel):
"""Identifying information about all people in a text."""
people: List[Person]
# Set up a parser
parser = PydanticOutputParser(pydantic_object=People)
prompt_template = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json` tags\n{format_instructions}",
),
("human", "{query}"),
]
).partial(format_instructions=parser.get_format_instructions())
query = "Anna is 23 years old and she is 6 feet tall"
print(prompt_template.invoke(query).to_string())
# 代入llm
chain = prompt_template | llm | parser
chain.invoke({"query": query})
Custom Parsing#
还可以使用 LangChain 表达式语言(LCEL)创建自定义提示和解析器,通过一个普通函数来解析来自模型的输出。 这种方式是llm刚开始的阶段,不推荐使用。
import json
import re
from typing import List
from langchain_core.messages import AIMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
class Person(BaseModel):
"""Information about a person."""
name: str = Field(..., description="The name of the person")
height_in_meters: float = Field(
..., description="The height of the person expressed in meters."
)
class People(BaseModel):
"""Identifying information about all people in a text."""
people: List[Person]
# Prompt
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Output your answer as JSON that "
"matches the given schema: ```json\n{schema}\n```. "
"Make sure to wrap the answer in ```json and ``` tags",
),
("human", "{query}"),
]
).partial(schema=People.schema())
# Custom parser
def extract_json(message: AIMessage) -> List[dict]:
"""Extracts JSON content from a string where JSON is embedded between ```json and ``` tags.
Parameters:
text (str): The text containing the JSON content.
Returns:
list: A list of extracted JSON strings.
"""
text = message.content
# Define the regular expression pattern to match JSON blocks
pattern = r"```json(.*?)```"
# Find all non-overlapping matches of the pattern in the string
matches = re.findall(pattern, text, re.DOTALL)
# Return the list of matched JSON strings, stripping any leading or trailing whitespace
try:
return [json.loads(match.strip()) for match in matches]
except Exception:
raise ValueError(f"Failed to parse: {message}")
query = "Anna is 23 years old and she is 6 feet tall"
print(prompt.format_prompt(query=query).to_string())
chain = prompt | llm | extract_json
chain.invoke({"query": query})
如何使用chat models来调用工具#
官方文档: https://python.langchain.com/v0.2/docs/how_to/custom_tools/#creating-tools-from-functions
将tools传递给llm#
@tool用来定义工具, 在定义的时候需要通过类型参数,文档注释等等来声明工具的作用,名字,参数,返回只等,在默认状况下,此装饰器会把函数名当作工具名。
from langchain_core.tools import tool
@tool(return_direct=True)
def add(a: int, b: int) -> int:
"""Adds a and b."""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
print(type(add))
print(add.name)
print(add.args)
print(add.description)
# 声明工具,传递给llm
tools = [add, multiply]
llm_with_tools = llm.bind_tools(tools)
query = "What is 3 * 12? Also, what is 11 + 49?"
ai_msg = llm_with_tools.invoke(query)
要注意:LLM本身没有调用函数的能力,他的返回值只是告诉我们需要调用函数,调用哪些函数,入参是什么。
这些信息都封装在tool_calls方法中
ai_msg.tool_calls
说回到tool,他的类型是StructuredTool,他也是实现了Runnable接口,所以,他是可以直接通过invoke调用的, 可以直接在LCEL中使用的
add.invoke({"a":1,"b":1})
okk,对于上面的结果,就可以找到对应的tool,将llm中的调用tool的参数塞进去调用就完事。
for tool_call in ai_msg.tool_calls:
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
tool_msg = selected_tool.invoke(tool_call["args"])
print(tool_msg)
end