RAG检索增强#
RAG是什么?#
RAG全称Retrieval augmented generation LLM是在一个固定庞大的数据集上训练的,这就导致一些数据他获取不到,比如最新的数据,虽然LLM提供了微调的方式,但这种方式也比较昂贵,所以就有了RAG,RAG是将相关的信息提供给LLM,基于这些信息来回答问题。所以,他是一种便宜并且实用的技术。
RAG大体步骤如下
输入问题
在资料中找到和这个问题相关的数据
组成Prompt,和LLM交互
Embedding#
解决的是如何通过输入的问题找到相关的数据,这就说到向量化了。 向量化就是将输入的一段文本或者任意形式的数据转换为一组数字,这些数字表示的是这组数据的特点,这些数据在数学上用向量表示,存储这些数据的数据库叫做向量数据库。 具体可看:https://guangzhengli.com/blog/zh/vector-database/
RAG架构#
具体可看:https://python.langchain.com/v0.1/docs/use_cases/question_answering/#rag-architecture 主要有两点
Indexing 做数据索引和向量化
检索和生成 实际的RAG链,在运行时接收用户查询并从索引中检索相关数据,然后将其传递给模型。
Indexing#
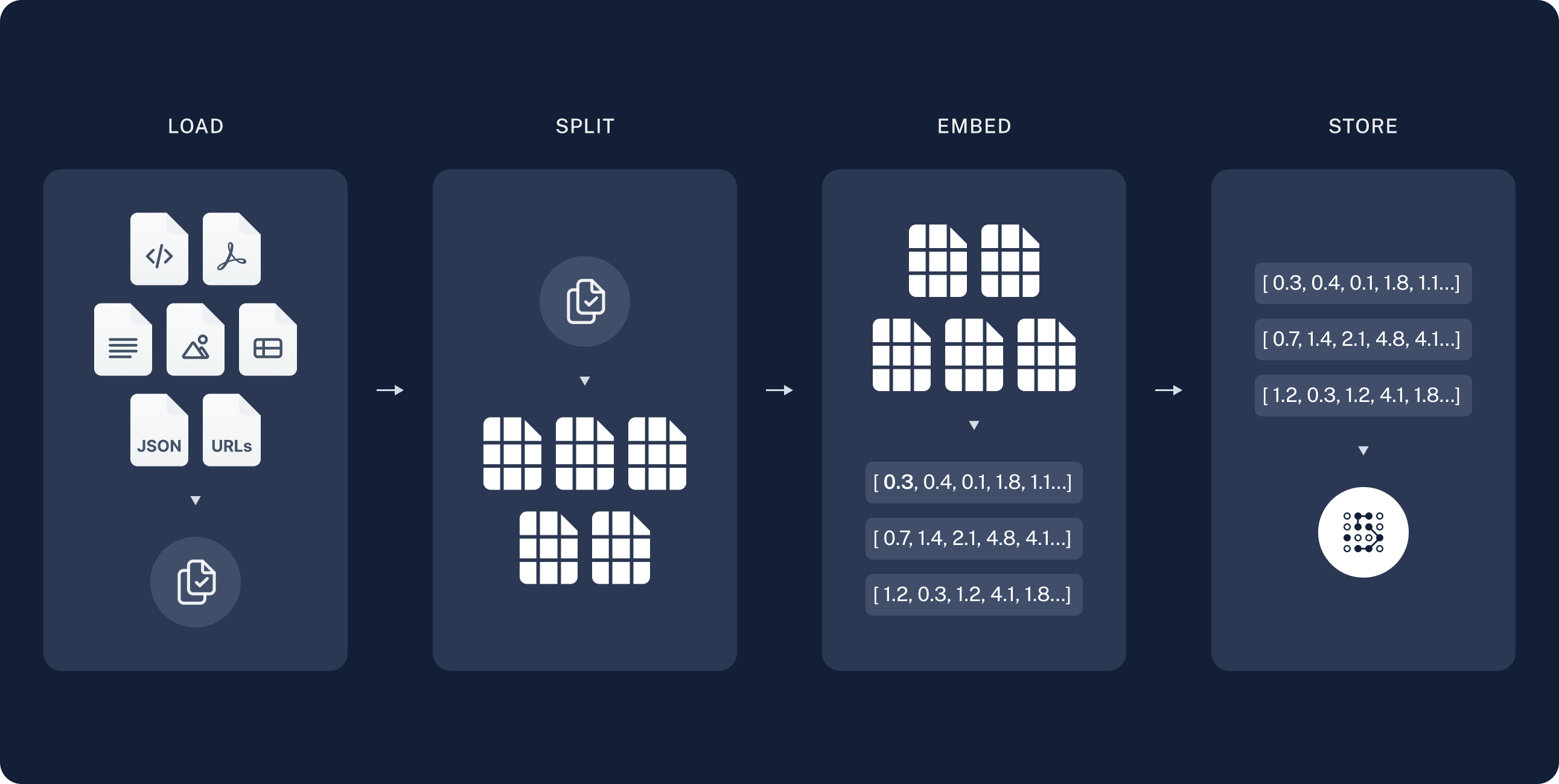 分为三步
分为三步
加载 加载数据,通过 DocumentLoaders.
切分 上一步加载后返回了Documents对象,这一步将它切分为小块,为了更好的索引和存储,大的快更难搜索,并且无法适应LLM的有限上下文窗口。
存储 将特征值存储
检索和生成#
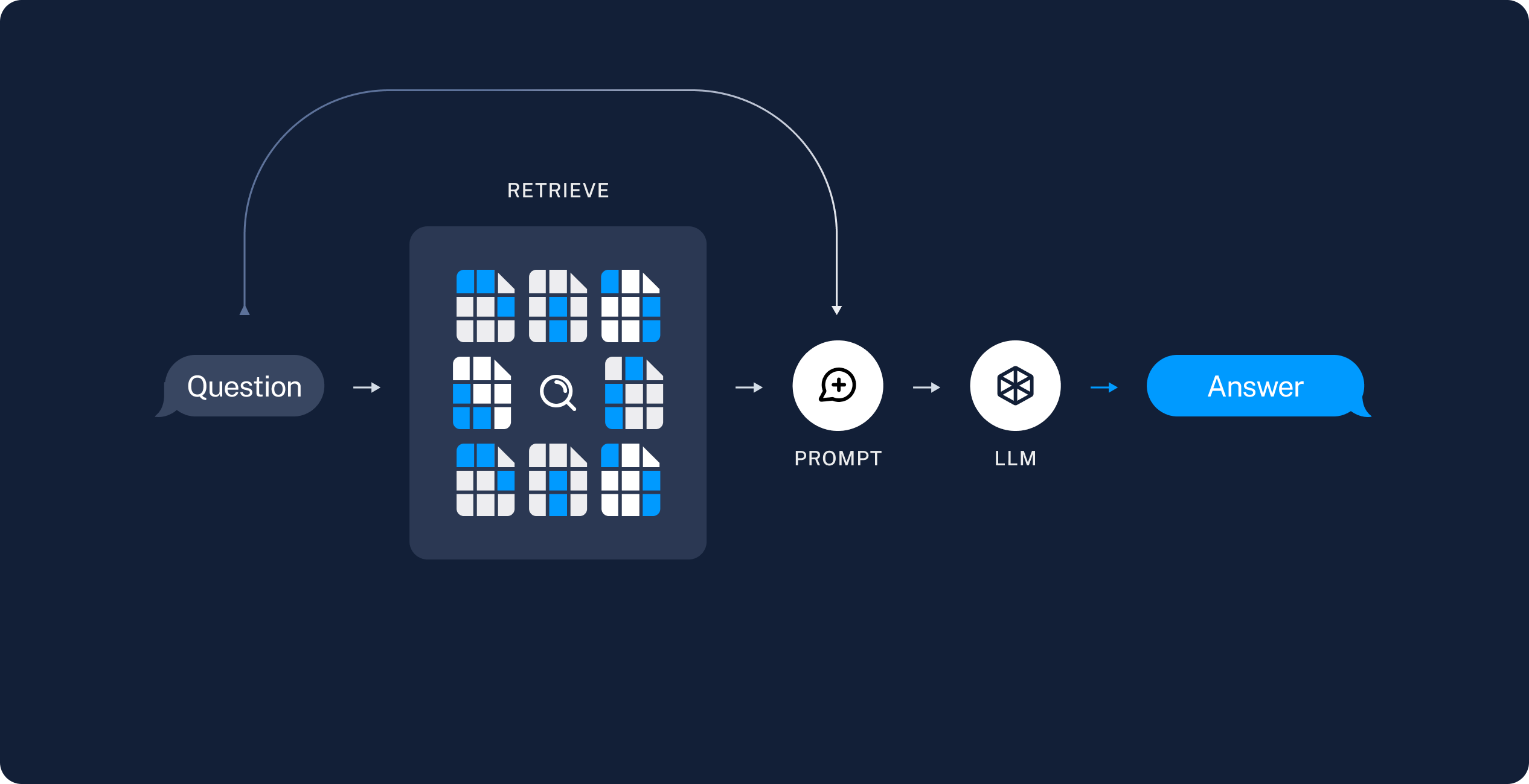
检索 从存储中找到相关的数据,使用Retriever.
生成 在生成的Prompt中嵌入相关数据和用户输入问题,llm生成答案
所以,在这章节中,步骤如下
加载资源
做Embedding,存储到向量数据库
输入问题,Embedding,在向量数据库中找相关文档
组成Prompt,和LLM交互
加载资源#
LangChain提供了很多的加载器,具体可看
https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/
在这里,我们加载html
from langchain_community.document_loaders import WebBaseLoader
import langchain
langchain.debug=True
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader(
web_paths=("https://daliuchen.github.io/langchain-guide/intro.html",)
)
docs = loader.load()
print(docs)
切分chunk#
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200) # 每500个字符为一块,两个块之间交替重合200个字符
splits = text_splitter.split_documents(docs)
print(splits)
print(len(splits))
Embedding#
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
vectorstore.similarity_search("LangChain特点",k=1)
套入Prompt中生成#
from langchain import hub
from langchain_core.prompts import ChatPromptTemplate
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt") # 从LangChainhub上拿到已经写好的promot
prompt.messages
# 从上面看到,有两个参数,context,和question
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
rag_chain = (
{"context": retriever , "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("LangChain是什么?")
虽然上面已经拿到了答案,但是细看promot中发现,在从向量数据库中查找完后,format Prompt的时候没有format Document。 所以,应该添加一个方法,在检索之后
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("LangChain的特点是什么")
这一章只是介绍了RAG的基本思路和简单demo,在后续,会有复杂有趣的示例。