RAG 一些相关问题#
RAG返回source#
返回本次回答引用了哪些文档。
通过create_retrieval_chain来做,代码如下
import bs4
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.globals import set_debug
set_debug(True)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# 1. Load, chunk and index the contents of the blog to create a retriever.
loader = WebBaseLoader(
web_paths=("https://guangzhengli.com/blog/zh/vector-database/",),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
# 2. Incorporate the retriever into a question-answering chain.
system_prompt = (
"你是一个ai助手,回答用户的问题"
"使用下面的上下文来回答"
"如果你不知道,要回答我不知道"
"使用简短精炼的语句表单,最多三句话"
"\n\n"
"{context}" # 这里content的位置就是从向量数据库中找到数据之后,塞到Prompt的位置,
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)
print(rag_chain.get_prompts()[0].pretty_print())
print(rag_chain.get_prompts()[1].pretty_print())
result = rag_chain.invoke({"input": "向量数据库的优点是什么?"})
print(result)
result["context"][0]
如上所述。在返回值中,会返回完整的引用的document的切片
返回引用#
官网文档: https://python.langchain.com/v0.2/docs/how_to/qa_citations/
在这里我演示前面两种方式
使用工具调用来引用文档 ID;
使用工具调用来引用文档 ID 并提供文本片段;
# 在上面的例子中已经返回了这次回答所涉及的所有的文档内容,都是放在`context`中,在下面的两个例子中,会以这个例子为基础来做。
result["context"][0]
使用工具调用来引用文档#
原理:首先先给文档编号,指定文档id,通过模型支持的函数调用来实现,with_structured_output
from typing import List
from langchain_core.pydantic_v1 import BaseModel, Field
# 规定模型调用的工具,之前说过,对于`with_structured_output`的实现也是通过`bind_tools`来实现的
class CitedAnswer(BaseModel):
"""根据提供的来源回答用户问题,并引用所使用的来源。"""
answer: str = Field(
...,
description="根据提供的来源,回答用户的问题。",
)
citations: List[int] = Field(
...,
description="回答这个问题所引用的文档id",
)
下面是一个简单的原理说明demo,之后会将找到的document格式化为下面的样子,代入到promot中处理
structured_llm = llm.with_structured_output(CitedAnswer)
example_q = """What Brian's height?
Source: 1
Information: Suzy is 6'2"
Source: 2
Information: Jeremiah is blonde
Source: 3
Information: Brian is 3 inches shorter than Suzy"""
result = structured_llm.invoke(example_q)
result
from langchain_core.runnables import RunnablePassthrough
from langchain_core.documents import Document
# 有了上面的demo,这里对文档做编号,实现和上面一样的效果
def format_docs_with_id(docs: List[Document]) -> str:
"""这个函数是格式化输入文档,create_stuff_document 方法里面的实现和这个一样"""
formatted = [
f"Source ID: {i}\nArticle Title: {doc.metadata['title']}\nArticle Snippet: {doc.page_content}"
for i, doc in enumerate(docs)
]
return "\n\n" + "\n\n".join(formatted)
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs_with_id(x["context"])))
| prompt
| structured_llm
)
retrieve_docs = (lambda x: x["input"]) | retriever
chain = RunnablePassthrough.assign(context=retrieve_docs).assign(
answer=rag_chain_from_docs
)
result = chain.invoke({"input": "向量数据库的优点是什么?"})
print(result["answer"])
如上所述,返回了本次回答所引用的文档。。
这个例子对引用文档的id这个功能体现的不太明显,因为retriever是在向量数据库中找的,向量数据库只是返回了文章的片段。
但是如果retrieve是一个WikipediaRetriever的呢?对一个问题可能会搜索出不同的答案,这个时候document就不是一个片段,而是一整个文章,这个时候就体现出来了(本次回答引用了哪些文章)
比如豆包的在线搜索

返回引用的原文#
和上面实现的原理一致,这里让返回的结构更加的复杂了一下,增加了quote字段来返回引用的原文。
一般在经过chunk之后,文本已经变得小了,这里让模型直接返回文本会让结果变得更加的清晰。(ps:这里我觉得只是存在chunk的情况下,否则文本过大,也会增加token的消耗。)
from typing import List
from langchain_core.pydantic_v1 import BaseModel, Field
class Citation(BaseModel):
source_id: int = Field(
description="回答这个问题所引用的文档id",
)
quote: str = Field(
description="从指定来源中引用的原文,证明答案的正确性。",
)
class QuotedAnswer(BaseModel):
"""根据提供的来源回答用户问题,并引用所使用的来源。"""
answer: str = Field(
description="根据提供的来源,回答用户的问题。",
)
citations: List[Citation] = Field( description="从提供的来源中引用支持答案的内容。"
)
structured_llm = llm.with_structured_output(QuotedAnswer)
example_q = """What Brian's height?
Source: 1
Information: Suzy is 6'2"
Source: 2
Information: Jeremiah is blonde
Source: 3
Information: Brian is 3 inches shorter than Suzy"""
result = structured_llm.invoke(example_q)
result
按照既定要求,模型返回的数据中已经包含了原文。同样的,也可以将上面的代码修改成这个样子。
在retriever的时候如何做用户的隔离#
LangChain有很多的retriever,LangChain并没有封装这样的能力,隔离的底层实现还得是各个retriever的能力。 官网:https://python.langchain.com/v0.2/docs/how_to/qa_per_user/
下面的demo中处理一个场景,不同的用户有不同的知识库。
import bs4
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.globals import set_debug
set_debug(True)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
# 1. Load, chunk and index the contents of the blog to create a retriever.
loader = WebBaseLoader(
web_paths=("https://guangzhengli.com/blog/zh/vector-database/",),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(),collection_name="userA")
retrieverA = vectorstore.as_retriever()
# 用户B 加载的是 https://daliuchen.github.io/langchain-guide/content/section_10.html
loader = WebBaseLoader(
web_paths=("https://daliuchen.github.io/langchain-guide/content/section_10.html",),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(),collection_name="userB")
retrieverB = vectorstore.as_retriever()
retrieverB.invoke("chat History是什么?")
print(retrieverA.invoke("向量数据库的特点是什么?"))
print(retrieverB.invoke("chat History是什么?"))
如上所示,在Embedding之后,将结果存储在数据库,我采用的方式是使用不同的collection name来做,这是隔离的一个基本思路,在实际中也是,让用户连接,构建chain的时候,就可以指定该用户所对应的collection name,实现数据隔离。
如何在提取时处理长文本#
文档:https://python.langchain.com/v0.2/docs/how_to/extraction_long_text/
在处理文本的时候,会遇到文本太长超过llm的限制,有三种方式来处理
换一个模型(可能更加的简单且效果好)
将文本简单的分块,从每个块中提取内容
对文本做RAG,对每个块做index,和问题相关的块做提取
下面的demo演示了2,3两个方法
# 准备
import re
import requests
from langchain_community.document_loaders import BSHTMLLoader
# Download the content
response = requests.get("https://baike.baidu.com/item/比亚迪")
# Write it to a file
with open("/tmp/car.html", "w", encoding="utf-8") as f:
f.write(response.text)
# Load it with an HTML parser
loader = BSHTMLLoader("/tmp/car.html",bs_kwargs={"features": "html"})
document = loader.load()[0]
# Clean up code
# Replace consecutive new lines with a single new line
document.page_content = re.sub("\n\n+", "\n", document.page_content)
# 这是直接加载了一个网页,他是一个超长文本,
print(len(document.page_content))
from typing import List, Optional
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.pydantic_v1 import BaseModel, Field
class KeyDevelopment(BaseModel):
"""比亚迪车型的相关信息"""
year: int = Field(description="车的上市年份.")
car_name: str = Field(description="车的名字")
class ExtractionData(BaseModel):
"""比亚迪汽车车型的提取信息。"""
key_developments: List[KeyDevelopment]
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你擅长提取文本中比亚迪车型发布的重要节点,如果提取不到重要信息,则不提取任何内容",
),
("human", "{text}"),
]
)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
extractor = prompt | llm.with_structured_output(
schema=ExtractionData,
include_raw=False,
)
extractor.invoke({"text":document.page_content})
已经准备好了,下面开始干活
直接分块提取#
这种方式比较简单,将各个结果分块,各自去调用llm,走上面的提取逻辑,再将结果合并
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(
# Controls the size of each chunk
chunk_size=2000,
# Controls overlap between chunks
chunk_overlap=20,
)
texts = text_splitter.split_text(document.page_content)
# Limit just to the first 3 chunks
# so the code can be re-run quickly
first_few = texts[:3]
extractions = extractor.batch(
[{"text": text} for text in first_few],
{"max_concurrency": 5}, # limit the concurrency by passing max concurrency!
)
合并结果
key_developments = []
for extraction in extractions:
key_developments.extend(extraction.key_developments)
key_developments[:10]
对文本做RAG#
这种方式就是RAG,没什么新意可言。
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_core.runnables import RunnableLambda
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
texts = text_splitter.split_text(document.page_content)
vectorstore = Chroma.from_texts(texts, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(
search_kwargs={"k": 1}
) # Only extract from first document
rag_extractor = {
"text": retriever | (lambda docs: docs[0].page_content) # fetch content of top doc
} | extractor
results = rag_extractor.invoke("比亚迪有什么车型?")
for key_development in results.key_developments:
print(key_development)
只是使用Prompt不适用函数调用来生成结构化数据#
有些模型不支持函数调用(tool calling),想要返回结构化调用只能通过Prompt来做 如果有的模型指令跟随是比较好的,通过Prompt能输出结构化数据 通过下面的步骤来完成
指示 LLM 按照预期格式生成文本
使用输出解析器将模型的响应结构化为所需的 Python 对象。
这里需要使用PydanticOutputParser
from typing import List, Optional
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
class Person(BaseModel):
"""人的信息"""
name: str = Field(..., description="人名")
height_in_meters: float = Field(
..., description="人的身高,单位M"
)
class People(BaseModel):
"""文本中提取的关于人的所有信息"""
people: List[Person]
parser = PydanticOutputParser(pydantic_object=People)
# Prompt
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user query. Wrap the output in `json` tags\n{format_instructions}",
),
("human", "{query}"),
]
# partial的意思是copy一份,并且渲染一部分
).partial(format_instructions=parser.get_format_instructions())
print("format_instructions:\n",parser.get_format_instructions())
print("*"*50)
print(prompt.invoke({"query": "小明一米五,小高比小明高一米"}).to_messages()[0])
print("*"*50)
print(prompt.invoke({"query": "小明一米五,小高比小明高一米"}).to_messages()[1])
print("*"*50)
上面是完整的Prompt,通过pydantic定义的model,调用get_format_instructions方法后,会自动生成json的定义,所以这里不需要手动来做。
在将上面的promot传递给LLM后,LLM会返回既定要求的文本(json格式),这里需要手动做解析,如下
import json
from langchain_core.messages import AIMessage
# 自定义
## llm输出的值为 AIMessage
def extract_json(message: AIMessage) -> List[dict]:
"""Extracts JSON content from a string where JSON is embedded between ```json and ``` tags.
Parameters:
text (str): The text containing the JSON content.
Returns:
list: A list of extracted JSON strings.
"""
text = message.content
# Define the regular expression pattern to match JSON blocks
pattern = r"```json(.*?)```"
# Find all non-overlapping matches of the pattern in the string
matches = re.findall(pattern, text, re.DOTALL)
# Return the list of matched JSON strings, stripping any leading or trailing whitespace
try:
return [json.loads(match.strip()) for match in matches]
except Exception:
raise ValueError(f"Failed to parse: {message}")
query = "小明一米五,小高比小明高一米"
chain = prompt | llm | extract_json
chain.invoke({"query": query})
查看LangSmith如下:
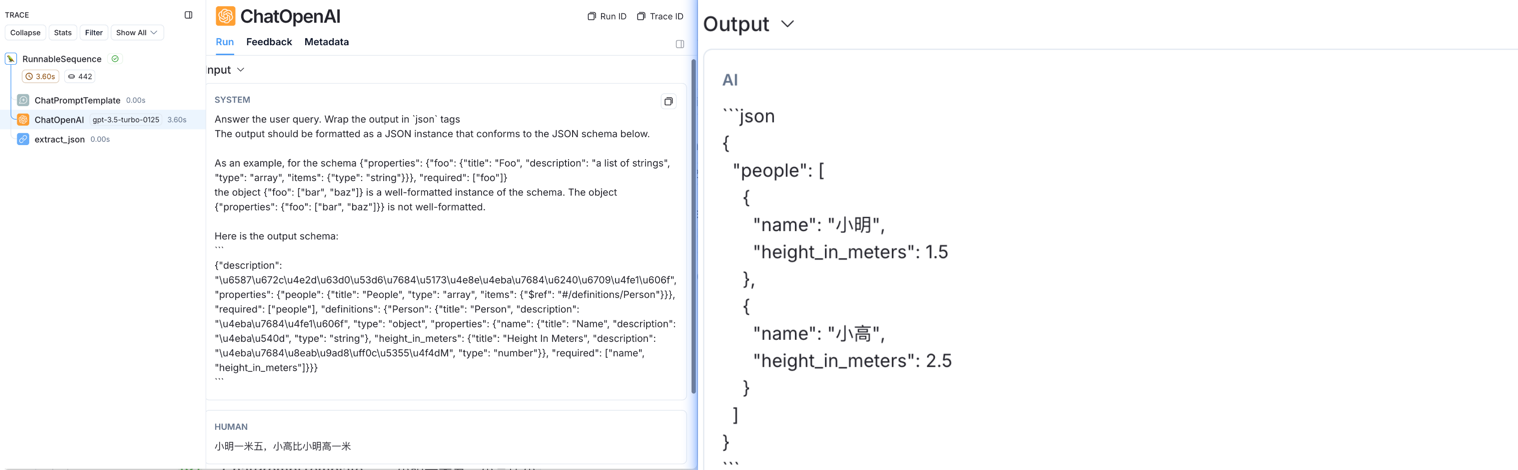
done!